I am working on implementing GenAi usecase on MTK platforms
I am using openlm-research/open_llama_3b_v2 · Hugging Face model and I am trying to run it following the 5.1.3 Tutorial for Large Language models present in Neuropilot 8.0.9 documentation.
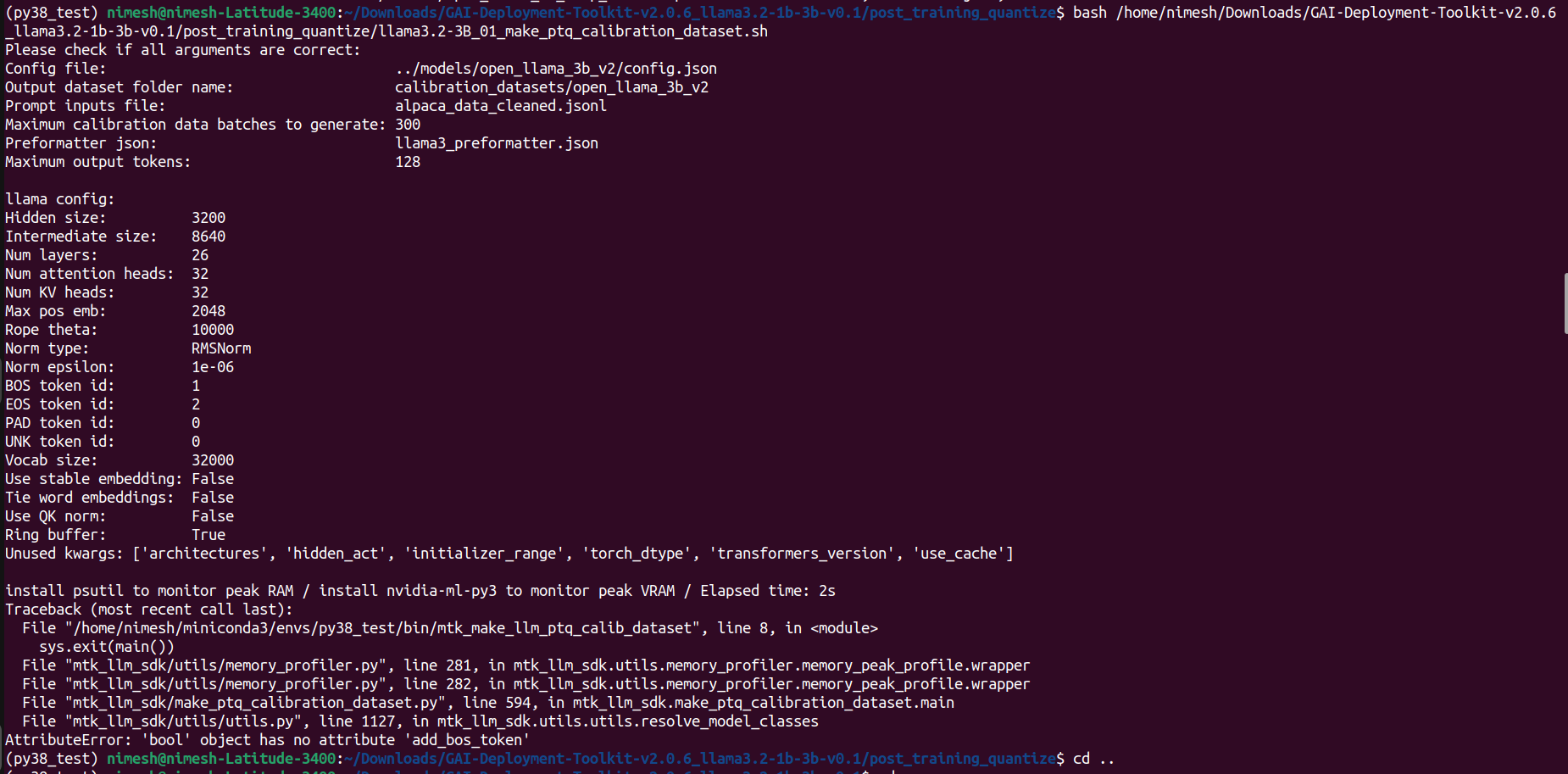
I am currently stuck at step 2 (Generating Caliberation Dataset):
Thank you for providing the detailed screenshots of the error you are encountering during Step 2 (Generating Calibration Dataset).
The error you are seeing may be related to a compatibility issue between that specific Open Llama variant and the toolkit’s current version.
Suggested Action: Try an Alternate Source Model
Since the name of your deployment toolkit (GAI-Deployment-Toolkit-v2.0.6_llama3.2-1b-3b-v0.1toolkit) explicitly references llama3.2, this could indicate that the toolkit is better optimized for or expected to work with the official Llama 3.2 models.
We recommend that you try switching to this model to see if it resolves the issue:meta-llama/Llama-3.2-3B (Hugging Face Link)
Please attempt the following steps:
Replace the current model (openlm-research/open_llama_3b_v2) with meta-llama/Llama-3.2-3B.
Restart the process from Step 2: Generating Calibration Dataset, as per the Neuropilot documentation.
If the problem persists after switching the model, please provide a new screenshot so we can continue troubleshooting.
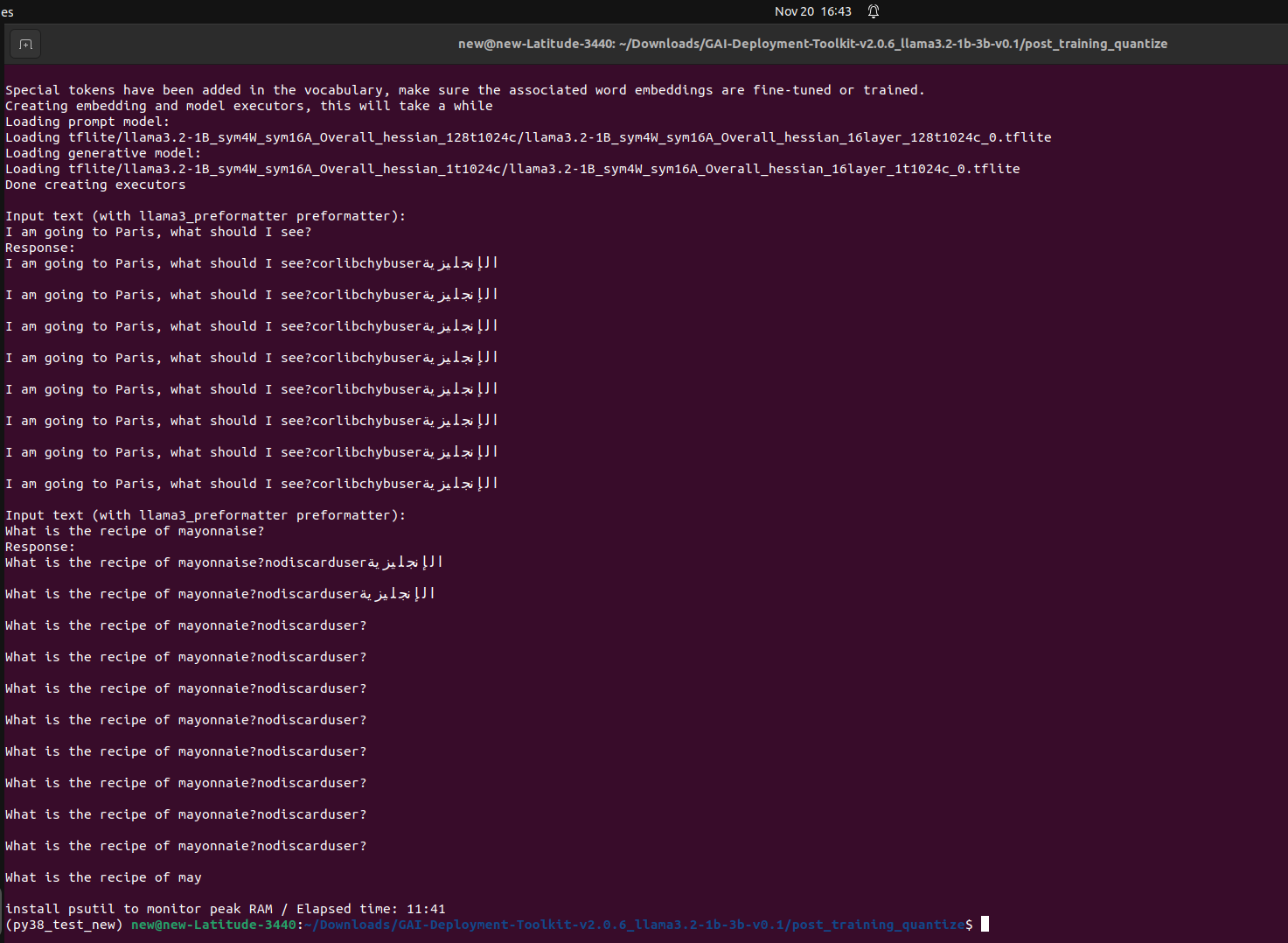
Thanks for your response, with your suggestion to make changes in config.json, I could resolve that error but further got the following error running the same command:
I am currently using 8.0.10 premium version of Neuropilot. In this and earlier versions, I have mtk_llm_sdk: 3.4.2 and 2.8.2 only. **I am unable to fetch 2.5.3 version.
**
I could find Mtk_converter: 8.13.0 and mtk_quantization: 8.2.0 from Neuropilot 8.0.7 version of the documentation.
If it is possible at your end, can you please share mtk_llm_sdk with 2.5.3 version with me so I can continue this task?
I continued with the further steps mentioned in the documentation, model compilation steps are finished and I am currently on 5.1.3.6.2. Pushing Dependencies to the Device
I am getting the same error if I use tokenizer.json or tokenizer.model. Can you please help me to debug it?
Also I want to confirm that in step 3c, “After the tokenizer files have been prepared, push them to the device using Android Debug Bridge (adb).” : by tokenizer files does it mean that added_tokens.yaml, vocab.txt, merges.txt need to be pushed to device or some other files need to be pushed as well?
I ll be really grateful if you can help me debug 3b and 3c steps of the documentation.
For every .bat file, I am getting command not found error.
Also, I do not have a rooted mobile phone, so I am planning to run this use case via Neuron Adapter/USDK instead of Neuron Runtime.
The reason the command can’t be found is that, starting from step 5.1.3.6, need to switch to a Windows PC to run the instructions. The .bat file is a Windows batch script, and it requires the following tools to already be available on Windows:
ndk-build
adb
Please open the built-in Windows terminal tool PowerShell, navigate to the directory where you placed the GAI toolkit, for example:
cd /path/to/GAI-Deployment-Toolkit-v2.0.6_llama3.2-1b-3b-v0.1/inference
./build_all_usdk.bat